Colin Rundel and I will be teaching a series of three virtual workshops in July 2020 on teaching statistics and data science online.
This post was contributed by Sara Stoudt (@sastoudt). Thank you Sara!
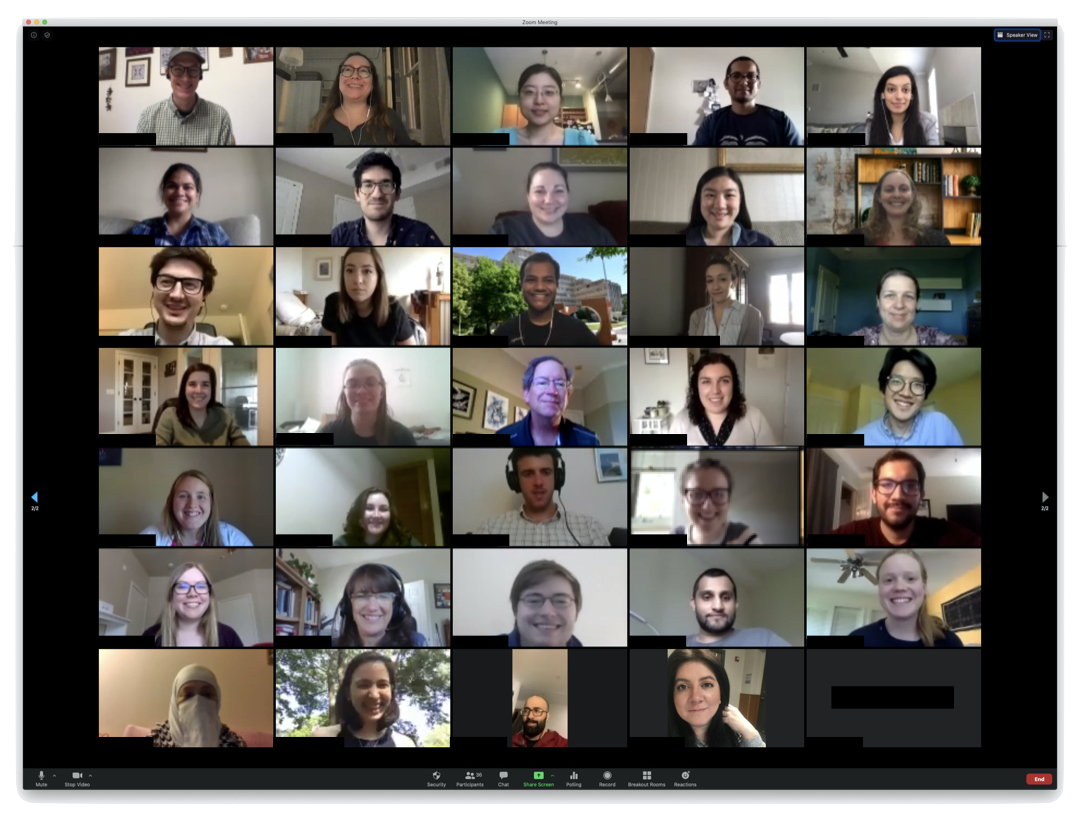
On May 15th and 20th the third Preparing for Careers in Teaching Statistics and Data Science Workshop was held. 37 graduate students and recent PhDs gathered (remotely of course) to learn from Allan Rossman (Cal Poly), Mine Çetinkaya-Rundel (University of Edinburgh, Duke, RStudio), Jo Hardin (Pomona), Beth Chance (Cal Poly), Lucy D’Agostino McGowan (Wake Forest), and Ulrike Genschel (Iowa State).
As recent, current, and future chairs of the American Statistical Association (ASA) Section on Statistics and Data Science Education, we have sent the following letter to Ron Wasserstein (Executive Director of ASA) and Bhramar Mukherjee (COPSS Chair) and requested that they share it with the COPSS Executive Committee.
Story of my first attempt at learning how to make generative art in R.

We haven’t written anything for a while because, well, I broke this website. Or maybe not me, but Hugo broke it. Or maybe blogdown did. They had disagreements about versions and didn’t want to play nicely with each other and I was too busy/tired/overwhelmed to play arbiter. Those adjectives still apply to how I’m feeling nowadays, but after updating R to version 4.0 and reinstalling all my packages, I decided now was the time to suck it up and fix things.
If you’ve ever been to an R workshop I gave, you probably heard me say “if the only thing you get out of this workshop is that RStudio projects are awesome and you should use them, this workshop was worth your time”. And I stand by this statement, they are awesome!1
But sometimes you just want a project-less RStudio! When, you ask? Imagine you have an RStudio project open where you’re writing course slides, or a blog post, or a package… And then imagine a student asks a coding question and you want to run their code quickly but don’t want to populate your environment with the objects that code creates.
It took me all of 30 minutes from starting this mini-project to writing this post. This is not meant to be a brag, but instead an ode to reproducibility. Last year for JSM 2018 I made a Shiny app to browse the conference schedule. I personally found that app really useful, and I know a few others did as well. And I saved my code in a GitHub repo.
Now that JSM 2019 is almost here, I thought I’d try my code again.

